后缀数组SA |
您所在的位置:网站首页 › cjson 数组 › 后缀数组SA |
后缀数组SA
|
引言
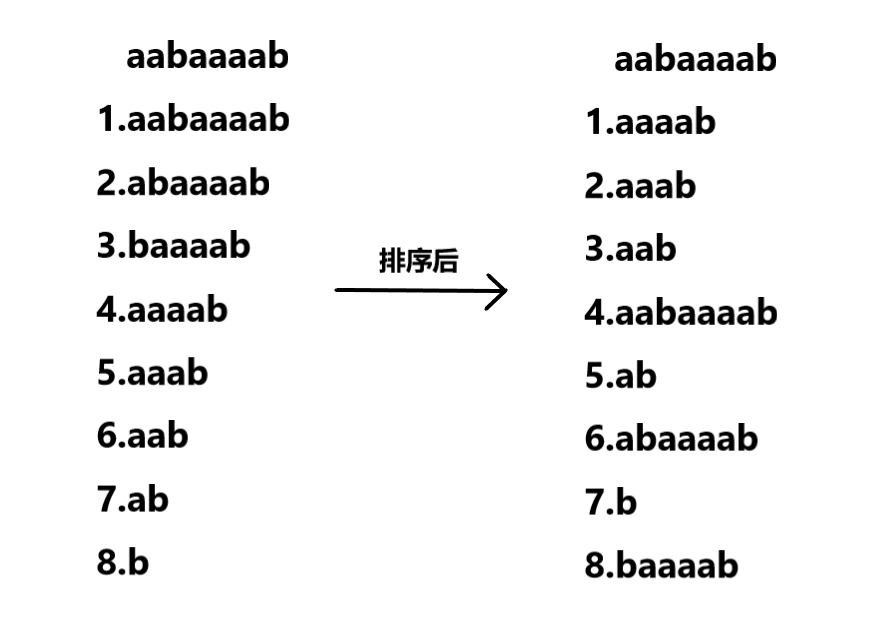
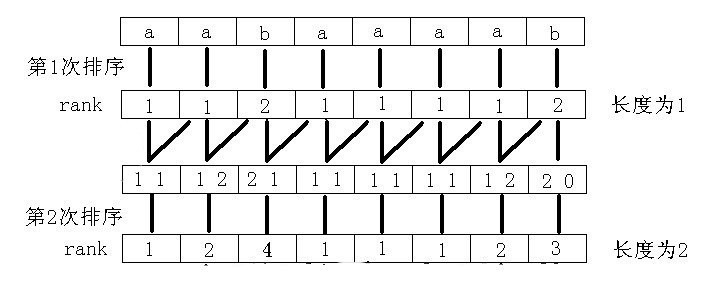
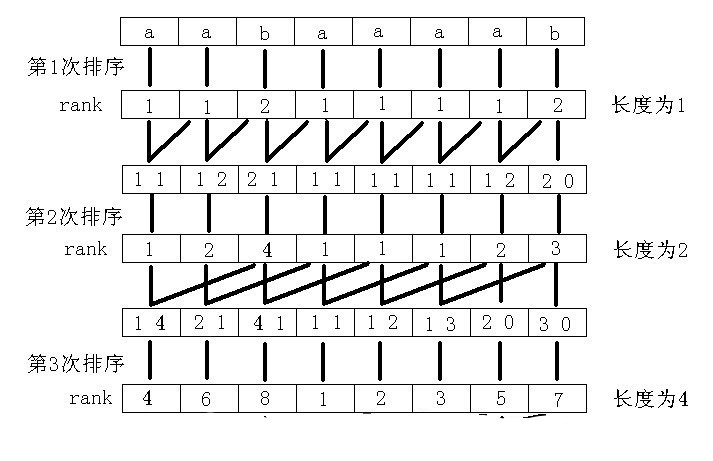
蒟蒻死磕了一周才算是对后缀数组入了门 后缀数组一般有两种求法 倍增法 O ( n l o g n ) O(nlogn) O(nlogn) 和 DC3算法 O ( n ) O(n) O(n) DC3法编程复杂度极高,空间开销也大,所以这里只讲一下倍增法,其实是蒟蒻并不会DC3 参考资料——罗穗骞《后缀数组——处理字符串的有力工具》 学习后缀数组前 你需要对基数排序有一定的了解 了解了基数排序之后我们从下面的问题引入后缀数组 Q:读入一个长度为 n 的字符串,把这个字符串的所有非空后缀按字典序从小到大排序 比如下图这样 先丢上一张图解(图片来源–2009集训队论文–《后缀数组——处理字符串的有力工具》) 以下简记从第 i i i位开始的后缀为后缀 i i i 一开始先对每个后缀的第一个字符排序 然后我们发现后缀 i i i的第2个字符就是后缀 i + 1 i+1 i+1的第1个字符 而每个后缀的第1个字符已经排好序,于是我们可以利用这一点对每个后缀的前两个字符排序 这时候我们再次发现后缀 i i i的第3、4个字符就是后缀 i + 2 i+2 i+2的前两个字符 于是再次利用这点对每个后缀的前四个字符排序 如此反复,排序前1个字符、前2个、前4个、前8个,最后排完前n个字符便完成了排序 这里很明显用到了倍增思想 直接描述可能还是不能很好的帮助理解 我们再以上图为例逐步解释 先对每个后缀的第一个字符排序 接着我们要巧妙地利用上一轮的rank来排序每个后缀的前2个字符 对于每个后缀的前2个字符,我们用一个两位的p进制数来表示(p为上一轮不同的rank数) 由于后缀 i i i的第2个字符就是后缀 i + 1 i+1 i+1的第1个字符 所以我们用来表示后缀 i i i前两个字符的k进制数就是 上一轮后缀 i i i第1个字符的rank作为最高位,后缀 i + 1 i+1 i+1第1个字符的rank作为第二位 不足的补0 这样利用基数排序,先比较最高位,也就相当于先按每个后缀第一个字符排序 再比较第二位,即如果有第一个字符相同的则再比较第二个字符rank大小 从而对后缀前两个字符完成了排序 此时我们得到了每个后缀前两个字符的rank 同理后缀 i i i的第3、4个字符就是后缀 i + 2 i+2 i+2的前两个字符 于是我们还可以用相同的方法对每个后缀的前四个字符排序 对于每个后缀的前4个字符,还是用一个两位的p进制数来表示(p为上一轮不同的rank数) 而这次的组成就是上一轮后缀 i i i前两个字符的rank作为最高位,后缀 i + 2 i+2 i+2前两个字符的rank作为第二位 同样利用基数排序完成后缀前四个字符的排序 同理完成前四个字符的排序后再次构造的两位p进制数为 上一轮后缀 i i i前四个字符的rank作为最高位,后缀 i + 4 i+4 i+4前四个字符的rank作为第二位 再次排序即完成前八个字符的排序 再次用形式化一些的语言描述以下这个过程 假设当前我们 已经知道每个后缀前k个字符的排序结果(rank) 由于后缀 i i i的第 i + k i+k i+k ~ i + 2 k − 1 i+2k-1 i+2k−1个字符与后缀 i + k i+k i+k的前 k k k个字符相同 所以利用这点将后缀 i i i的前k个字符的rank作为一个进制数的最高位 后缀 i + k i+k i+k的前 k k k个字符的rank作为这个进制数的第二位 将得到的n个数利用基数排序排序后即得到了每个后缀前 2 k 2k 2k个字符的rank 如此利用倍增每次排序长度翻倍,排序总次数为 l o g n logn logn 每次排序复杂度为 O ( m ) O(m) O(m)(m为当前排序时已经出现的不同的排名个数) 总时间复杂度为 O ( m l o g n ) O(mlogn) O(mlogn) 代码实现了解了上述算法的思路后考虑一下代码实现 似乎上面的算法并没有用到什么后缀数组啊,我们在这里开始引入这个概念 r a k [ i ] rak[i] rak[i]:后缀 i i i(前k个字符)的排名 s a [ i ] sa[i] sa[i]:当前排名为 i i i的后缀(前k个字符)开始的位置 (即后缀数组) t p [ i ] tp[i] tp[i]:与sa或rak相同,辅助基数排序,具体用法下面解释 t a x [ i ] tax[i] tax[i]:基数排序用的桶 先丢上一个完整的代码 //省去了数组定义之类乱七八糟的东西 void rsort() { for(int i=0;i int p=0; for(int i=n-k+1;i for(int i=0;i=H[i-1]+1 H[i]>=H[i−1]+1 证明设 后缀 k k k 是 后缀 i − 1 i-1 i−1 前一名的后缀,则它们的lcp长度是 H [ i − 1 ] H[i-1] H[i−1] 因为 后缀 k + 1 k+1 k+1 将排在 后缀 i i i 的前面 且 后缀 k + 1 k+1 k+1 和 后缀 i i i 的lcp长度是 H [ i − 1 ] − 1 H[i-1]-1 H[i−1]−1 所以 后缀 i i i 和在它前一名的后缀的lcp至少是 H [ i − 1 ] − 1 H[i-1]-1 H[i−1]−1 按照 H [ 1 ] , H [ 2 ] , … … , H [ n ] H[1],H[2],……,H[n] H[1],H[2],……,H[n]的顺序计算,并利用 H 数组的性质 时间复杂度可以降为 O ( n ) O(n) O(n) //字符串从数组下标1开始储存 void getH() { int k=0; for(int i=1;i |
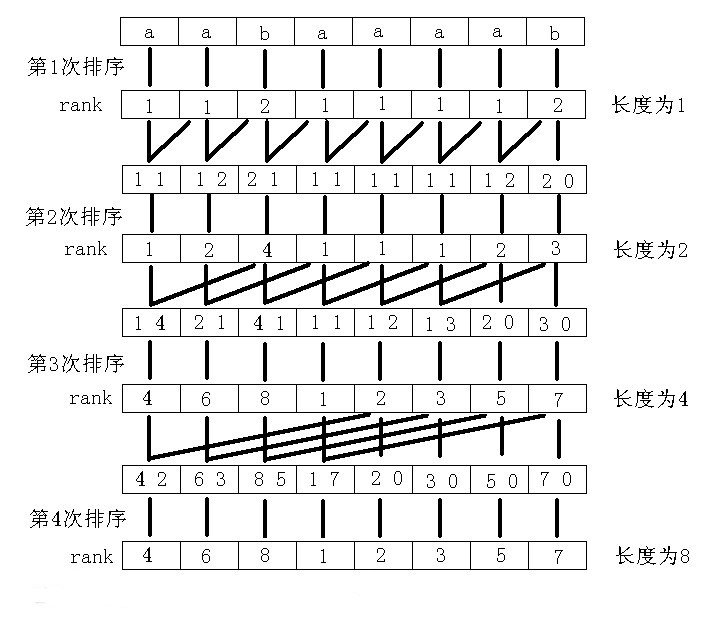 我知道你们一定看得一脸懵逼,反正我第一次就是这样 那么就先讲解一下这个排序的大致思路
我知道你们一定看得一脸懵逼,反正我第一次就是这样 那么就先讲解一下这个排序的大致思路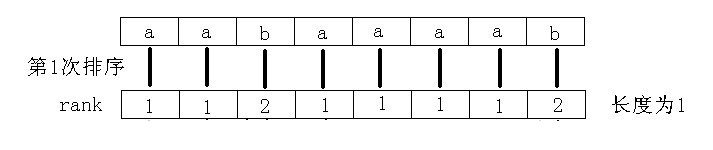
【本文地址】